
결과보고에 앞서
실리콘브릿지는 아마존 클라우드 서버(AWS)를 기반으로 한 무인 주차관제 플랫폼을 만들어 제공하고 있습니다.
국내 최초 AWS 클라우드 환경 위에 주차 관제 플랫폼을 구축해 말단 기기에 구애받지 않는 독보적인 무인 차량 관제 시스템을 선보이며 카카오모빌리티, LG S&I의 기술 협력사로 활동하고 있습니다.
최근 주차 관제 시장에 인공 지능(AI) 바람이 불면서 로컬 서버 기반에서 클라우드 기술 기반으로 변화를 꾀하는 기업들이 많아졌는데요,
실리콘브릿지 또한 한 단계 더 차별화된 기술을 선보이기 위해 자체 연구개발을 끊이지 않고 있답니다.
2020 하반기 AI데이터바우처 최종 결과 보고
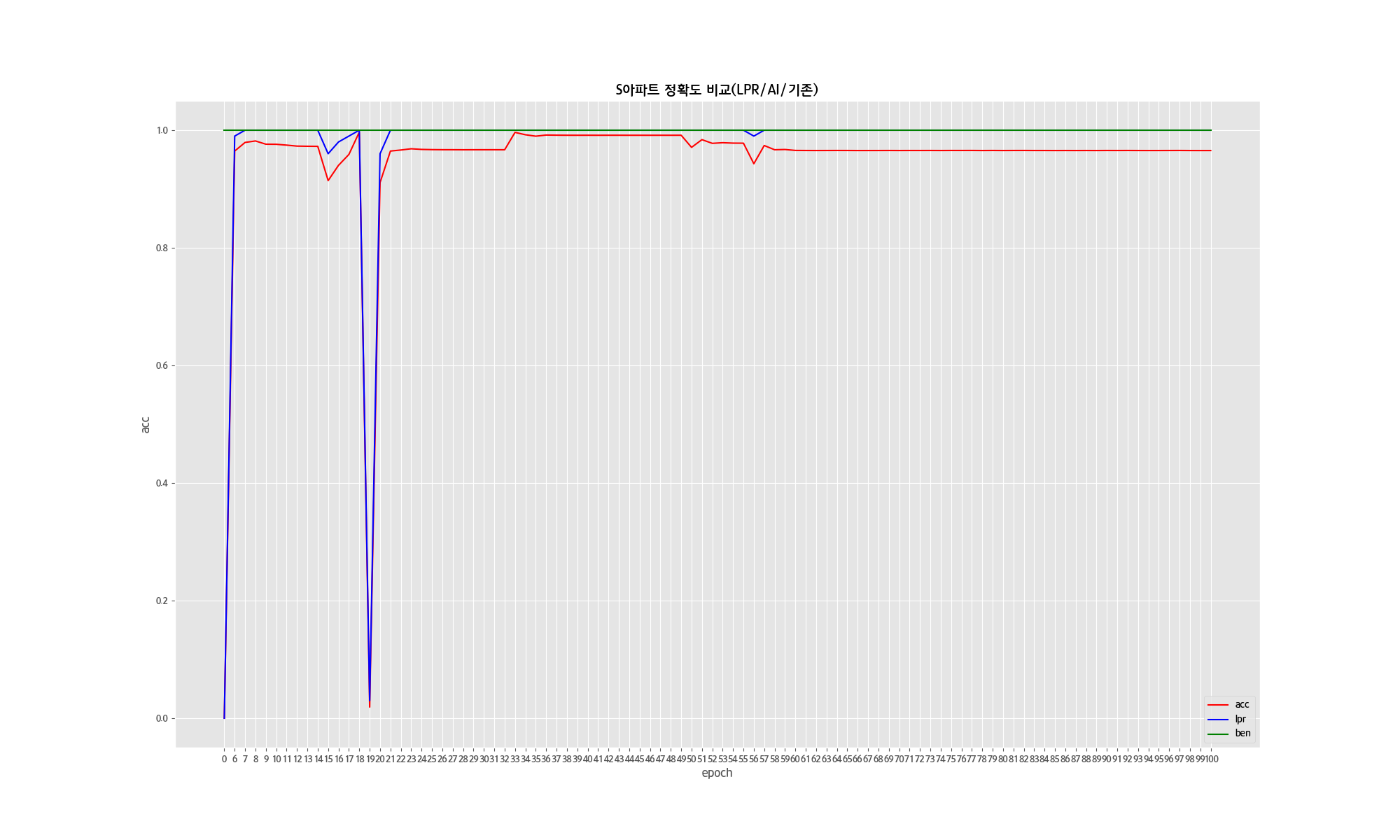
실리콘브릿지의 차량번호인식기는 평균 99.8%의 정인식률을 보이고 있습니다.
하지만 기계장치인 만큼 0.2%이내의 차량 미인식,오인식률을 가지고 있는데요, 이 오차를 잡는 것이 실리콘브릿지의 오랜 과제였습니다.
차량번호판 훼손, 오물 묻음, 빛 번짐, 저조도 등으로 차량번호가 제대로 인식되지 않는 문제는 저희 뿐만이 아니라 주차관제 업체 모두의 과제이기도 해서, AI 데이터바우처 지원 때 연구의 타당성을 인정받기도 했습니다.
그렇다면 약 4개월 간의 지원 사업을 받은 이후 어떤 기술적 성과를 얻게 되었을까요?
1. 500,000개의 가공 데이터로 학습한 AI 딥러닝 모델
실리콘브릿지는 2020년 6월 도로교통공단의 공식 성능 평가 시험을 시행한 적이 있는데 해당 테스트 결과로 인식률 100%, 오인식률 0.2%의 성적을 받았었습니다.
500,000개의 데이터를 전부 학습하고 공식 성능 평가 시험을 본 장소에서 2020년 12월 13일 자체 테스트를 시행한 결과, 100%의 인식률(오인식률 0%)를 기록했습니다.
2. 극한의 상황에서도 높은 인식률을 보이는 모델 개발
측면 촬영, 차량번호판의 심한 훼손, 오물 및 빛 번짐, 저조도 등으로 기존 서비스에서 아예 감지하지 못 한 인식률 0% 이미지 112장을 테스트 한 결과, 82.27%의 인식률을 보였습니다.
즉, 기존 100% 인식했던 번호판은 100% 그대로 인식을 하면서, 극한의 환경에서 아예 인식하지 못했던 0% 인식률의 차량번호판 또한 82% 이상의 인식률을 보이는 성과를 얻게 된 것입니다.

물론 아직 공식적으로 상용화 하기에는 모델 경량화 작업 등 신경써야 하는 부분들이 많이 남아있습니다.
하지만 기존 주차 관제 시장의 고질적인 문제에 대한 실마리를 얻었다는 점에서 소중한 한 걸음을 내딛은 거라 생각합니다.
고객분들이 믿어주시는 만큼 조금씩이지만 꾸준히, 발전하는 모습을 보여드리겠습니다.
감사합니다.
AI데이터바우처 사업을 마치며 ::
부설연구소
조OO 주임연구원 인터뷰
01. 데이터 바우처 사업의 참여 동기와 목적에 대해 알려주세요.
자사는 5년 동안 수집한 억 단위의 주차 관제 데이터를 갖고 있지만, AI 모델에 사용할 수 있는 정제된 데이터가 없었습니다. 자사 내에서 데이터 가공 작업을 진행하고 있었지만 시간, 비용 등 자원이 너무 많이 소요되었습니다.
그러던 중 ‘AI 데이터 바우처 지원 사업’이라는 데이터 가공을 지원 해주는 사업을 발견하고 ‘데이터 가공’이라는 자사가 가장 필요했던 부분을 해결 할 수 있었습니다.
02. AI 인식률 향상 딥러닝 구축모델의 개발은 어떻게 진행됐나요?
데이터 바우처 지원 사업에 적용된 딥러닝 모델 구축은 크게 3단계로 구성 했습니다.
첫 번째로 데이터 바우처 지원 산업을 신청 한 이유인 가공할 데이터 전달 및 산출물 수신, 두 번째로 실제 성과를 얻기 위한 차량 번호판 인식 모델 구축, 마지막으로 모델의 성능을 평가하기 위한 정확도 측정 및 산출물 검수로 구성했습니다.
03. 개발 과정에서 난항이었던 점이 있었나요?
자사에 가공된 데이터가 부족했기 때문에 50만 장의 가공된 데이터를 검수할 수 있는 모델이 없었고, 수작업으로 진행하기에도 데이터 바우처 사업의 기간이 짧았습니다.
데이터를 검수하지 않는다면, 오류가 있는 산출물이 모델에 영향을 줄 수 있기 때문에 검수 프로세스 구축을 가장 중요시 했습니다.
04. 개발 과정의 난항을 어떻게 해결했나요?
이 문제를 해결하기 위해서 데이터 바우처 지원 전에 먼저 다양한 검출 및 인식(Detection, recognition) 모델을 분석했습니다.
자사가 기존에 갖고 있었던 5,000 ~ 10,000장의 데이터를 전이 학습(transfer learning)했을 때 가장 정확도가 높았던 모델을 선정했습니다.
데이터 바우처 진행 중에는 500,000장의 데이터를 한번에 전달하는 것이 아니라 가공 프로세스를 4단계에 걸쳐서 125,000장 씩 진행했습니다. 각 단계마다 전이 학습을 해서 1단계에서는 86%의 정확도를 갖는 모델로 검수를 하고 나머지 14%에 대해서 수작업으로 검수를 진행했습니다.
각 단계를 거치면서 정확도가 점차 높아져 마지막에는 모든 데이터를 모델이 검수 할 수 있었습니다.
05. 사업진행 전후로 오인식률이 높던 차량번호판들의 인식률이 어떻게 바뀌었을까요?
데이터 바우처 사업 진행 전에 도로 교통 공단 성능 평가 데이터 기준 정확도는 73.76% 였지만, 가공 프로세스 4단계 별로 1단계에 90%, 2단계에 98.93% 3단계에 99.31% 마지막으로 100%까지 달성할 수 있었습니다.
06. 딥러닝 인식 모델의 장단점을 알기 쉽게 설명해 주실 수 있나요?
딥러닝에도 다양한 종류가 있고, 그마다 다양한 특징들이 있어서 한마디로 정의하기 어렵습니다.
데이터 바우처에 사용했던 딥러닝 모델로 제한한다면, 기존 LPR 보다 노이즈에 강력하다는 장점이 있습니다.
빛번짐, 저조도, 측면 촬영, 번호판 훼손 등 다양한 노이즈에 잘 대응할 수 있습니다.
단점으로는 데이터 바우처에 지원한 목적처럼 모델에 필요한 데이터 셋이 많이 필요하다는 점입니다.
데이터 셋이 적으면 다양한 노이즈는 커녕 깔끔한 이미지도 제대로 처리를 못할 수 있습니다.
07. 인터뷰를 진행해주셔서 감사합니다. 마지막으로 향후 계획에 대해 한 말씀 부탁드립니다.
고성능 컴퓨터에서만 돌아가는 연구를 위한 모델이 아니라 모든 사람들이 체감할 수 있는 모델을 만들고자 합니다.
AI 데이터 바우처를 통해 높은 정확도의 모델을 얻을 수 있었습니다.
이제 이 모델을 다양한 사람들에게 제공하기 위해 모델 경량화 및 SaaS 기반 API를 구축할 계획입니다.
'실리콘브릿지 새소식' 카테고리의 다른 글
| [AI데이터바우처지원사업] 중간평가보고 -2- (0) | 2020.12.04 |
|---|---|
| [영상출처 YTN뉴스] 국방무 무단침입차량 사건으로 보는 주차관제시스템의 한계와 개선 솔루션 (0) | 2020.12.03 |
| [2020 AI데이터바우처지원사업] 향상된 차량번호인식 AI 딥러닝 모델 개발 진행상황 공유 (0) | 2020.11.24 |
| 실리콘브릿지 무인주차관제시스템 아이박스 EYEVACS™ 조달청 벤처나라 벤처창업혁신조달상품 선정! (0) | 2020.11.12 |
| [2020 하반기 소식] 실리콘브릿지 AI데이터바우처지원사업 우선협약대상 선정 (0) | 2020.10.28 |